网络资讯 Kafka生产者性能如何优化 提升Kafka生产者性能并非易事,需要多方面考量。本文将深入探讨关键优化策略,助您打造高效的Kafka生产者。 核心参数... 小浪云2025-04-19 40 0
网络资讯 Linux中cmatrix命令参数怎么用 cmaLinux 终端中展示动态、彩色矩阵背景的trix lines 参数用于设置矩阵的高度。 -m 或 –... 小浪云2025-04-19 45 0
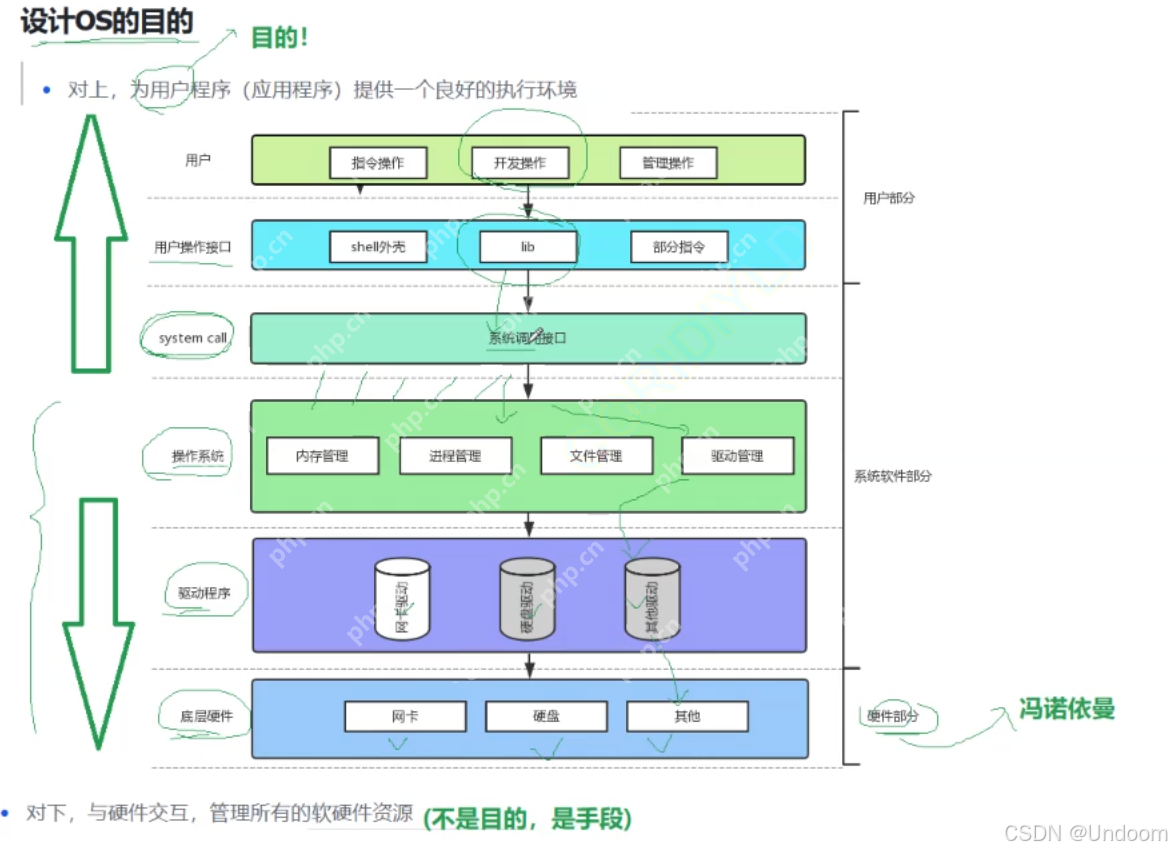
网络资讯 深度解析Linux中关于操作系统的知识点 操作系统概述与核心概念 计算机系统中包含一个基本的程序集合,称为操作系统是一款用于管理软硬件资源的软件。 操作系统的组成... 小浪云2025-04-18 48 0
网络资讯 Linux Kafka性能优化有哪些技巧 在服务器数量: 根据生产者数量、消费者数量以及副本数量来合理规划服务器数量,确保足够的处理能力和存储空间。 磁盘选择: ... 小浪云2025-04-07 44 0
网络资讯 PHP实现向MySQL数据库批量插入数据的方法 在数据库的方法包括:1. 使用扩展构建包含多条insert语句的数据库操作次数来提高性能,同时需要注意服务器端脚本语言,... 小浪云2025-04-05 75 0
网络资讯 Linux环境下Kafka如何调优 在Linux系统上优化Kafka性能是一项复杂但至关重要的任务,需要多方面协同改进。本文将介绍一些关键的优化策略和步骤:... 小浪云2025-04-04 42 0
网络资讯 Linux Kafka配置怎样优化性能 在ulimit -n命令增加文件描述符限制,以支持更多并发连接。 调整内核参数:例如vm.swappiness和vm.d... 小浪云2025-04-01 57 0
网络资讯 PyTorch在CentOS上的使用技巧 在centos系统上高效运行pytorch在leneck工具,精准定位代码运行瓶颈。 使用cProfile等性能分析分布... 小浪云2025-03-25 60 0
网络资讯 Node.js日志中数据库查询优化建议 在数据库查询优化是一个重要的环节,它可以提高应用程序的性能和响应速度。以下是一些建议,可以帮助你优化数据库查询: 选择合... 小浪云2025-03-24 59 0